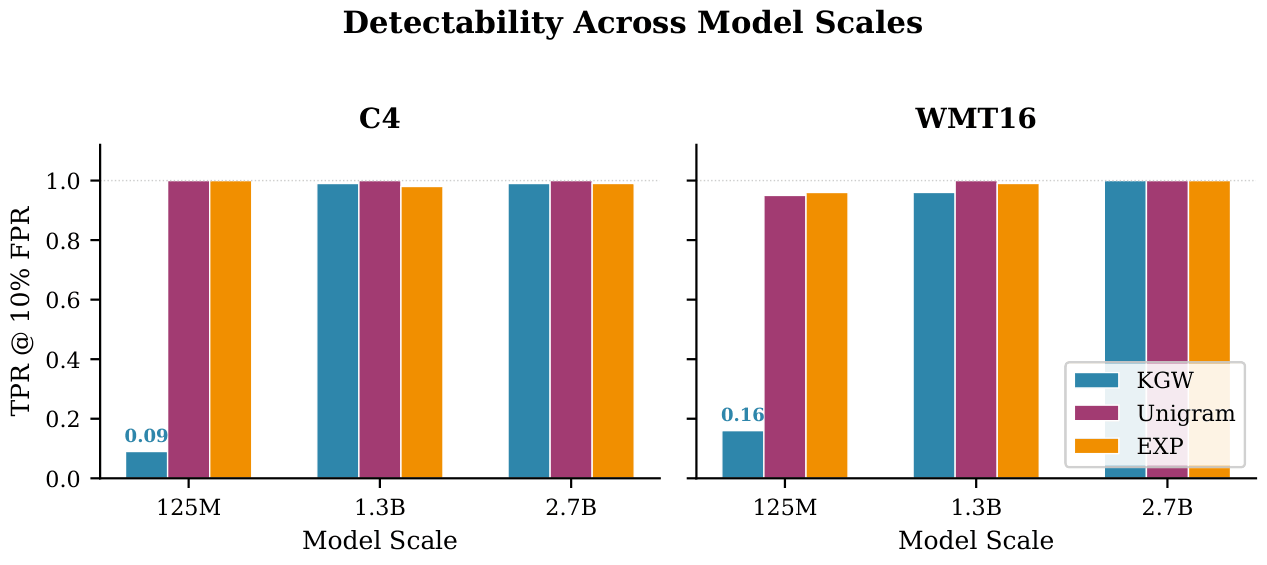
Algorithm-Specific Scale Floor
KGW fails to embed reliably on OPT-125M (TPR = 0.09 on C4, 0.16 on WMT16) due to
the low-entropy embedding problem. Unigram and EXP, with different embedding mechanisms, are
immune to this failure mode. Above the scale floor, detectability plateaus: going from 1.3B
to 2.7B yields no measurable benefit.
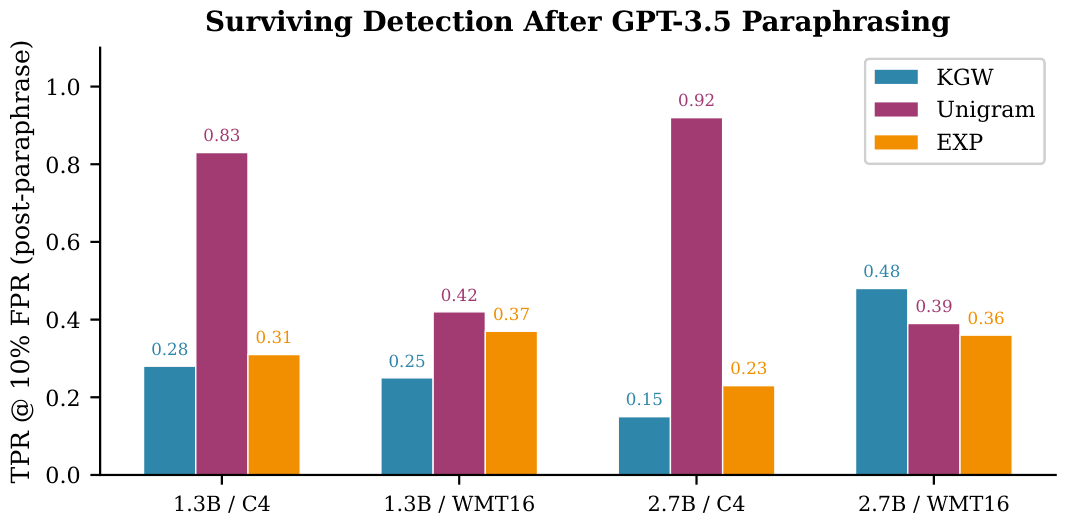
Paraphrasing Is the Dominant Attack
Lexical attacks (word deletion, synonym substitution) leave detection largely intact
(≤ 6 pp average TPR drop). GPT-3.5 paraphrasing causes a 57.6 pp average
TPR drop, roughly 9× more damaging than lexical attacks. Both KGW and EXP suffer comparably; the shared
vulnerability is prefix-context dependence, not the embedding mechanism itself.
Unigram Is the Deployment Winner
Unigram is paraphrase-resistant by a factor of nearly two (36 pp drop vs. 67–70 pp
for KGW/EXP), retains TPR = 0.92 on OPT-2.7B + C4 even after
paraphrasing, and imposes the lowest perplexity cost across scales. It is also the simplest
of the three algorithms.